Introduction¶
Functionality Overview¶
This toolkit defines a unified experimnts framework for semi-supervised learning algorithms. Besides, it also provides some state-of-the-art safe semi-supervised learning (Safe SSL) algorithms handling bad data quality and model uncertainty. We design the framework under as less as assumption except for supervised setting. Therefore, it’s convenient to incorporate different algorithms for different settings into our experiment framework. We hope this unified framework can help researchers and other users evaluate machine learning algorithms in a light manner.
Pipeline of Safe SSL¶
In this toolkit, we foucus on three critical aspects to improve the safeness of semi-supervised learning: data quality, model uncertainty and measure diversity.
- As for data quality, the graph used in graph-based SSL and risky unlabeled samples may degenerate the performance.
- In the model part, we now understand that the exploitation of unlabeled data naturally leads to more than one model option, and inadequate choice may lead to poor performance.
- In practical applications, the performance measures are often diverse, so the safeness should also be considered under different measures.
The figure below provides an illustration of the three aspects of the safeness problem in semi-supervised learning.
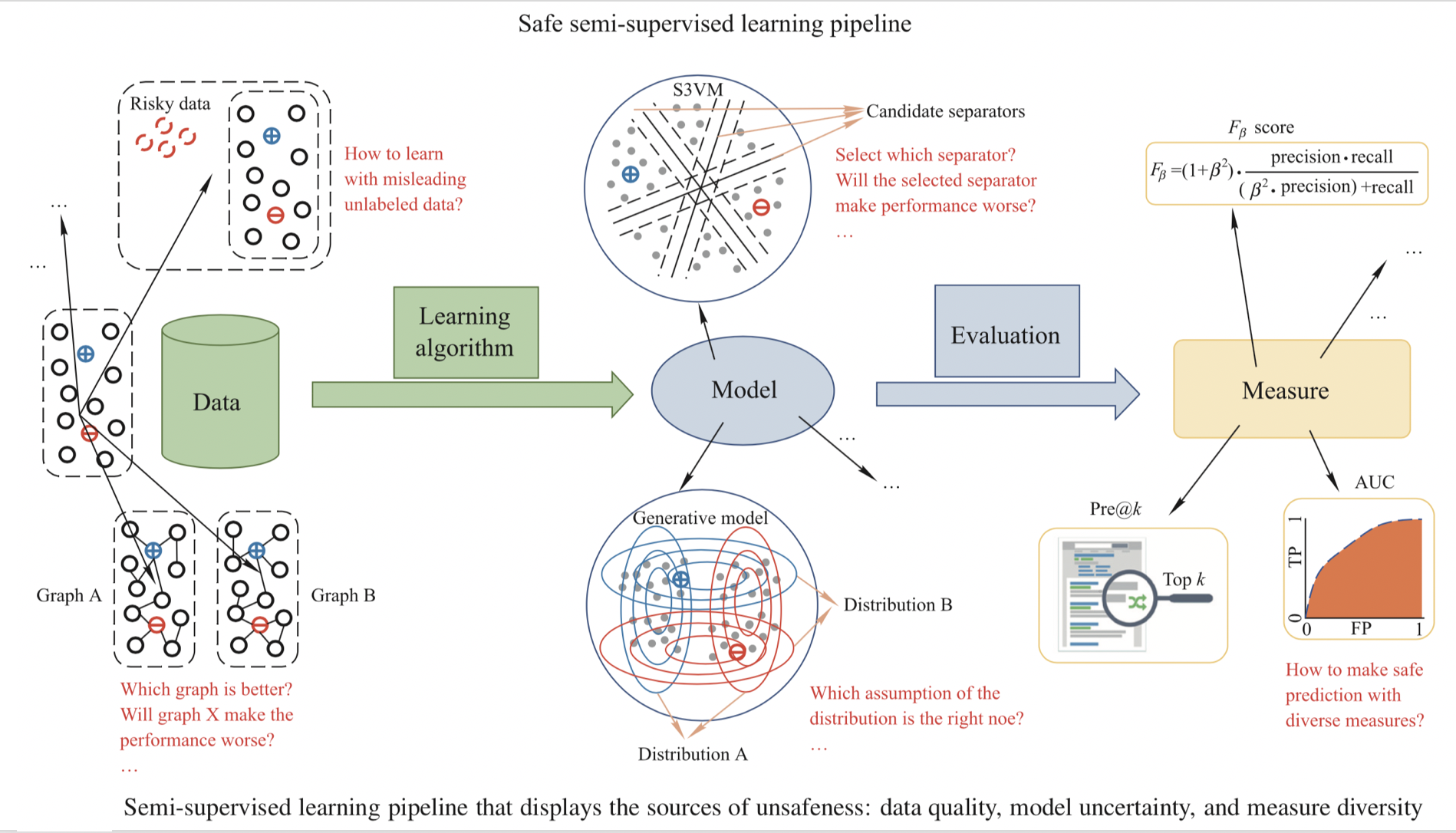
Then, we will introduce the corresponding algorithms in detail in data quality module, model uncertainty module and ensemble module.
For more details about safe semi-supervised learning, we recommend users to read Safe semi-supervised learning: a brief introduction.
Packages and Modules¶
Here, we will give a brief introduction of the submodules in this package.
- Classification: Classical semi-supervised learning algorithms.
- Data Quality: Algorithms to solve the safeness of graph-based SSL algorithms.
- Model Uncertainty: Algorithms to eliminate the uncertainty of classifiers.
- Ensemble: Ensemble methods to provide a safer prediction when given a set of training models or prediction results.
- Experiments: A class which designs experiment process.
- Estimator: A class of machine learning algorithms.
- Metric: Metric functions used to evaluate the prediction given ground-truth.
- Wrapper: Helper classes to wrap the third-party packages into the experiments in this package.